In this project, I will implement and deploy diffusion models for image generation, exploring their potential for creating high-quality, realistic visuals. The project is divided into two distinct parts, each with its own set of goals and deadlines (detailed below). This step-by-step approach will ensure a comprehensive understanding of diffusion-based generative modeling techniques.
Setup
Using DeepFloyd's Stage 1 function, I generated images from text prompts, followed by applying Stage 2 for super-resolution to enhance the output quality. My
selected seed was 180, ensuring reproducibility across all experiments. The prompts I used were:
- "An oil painting of a snowy mountain village"
- "A man wearing a hat"
- "A rocket ship"
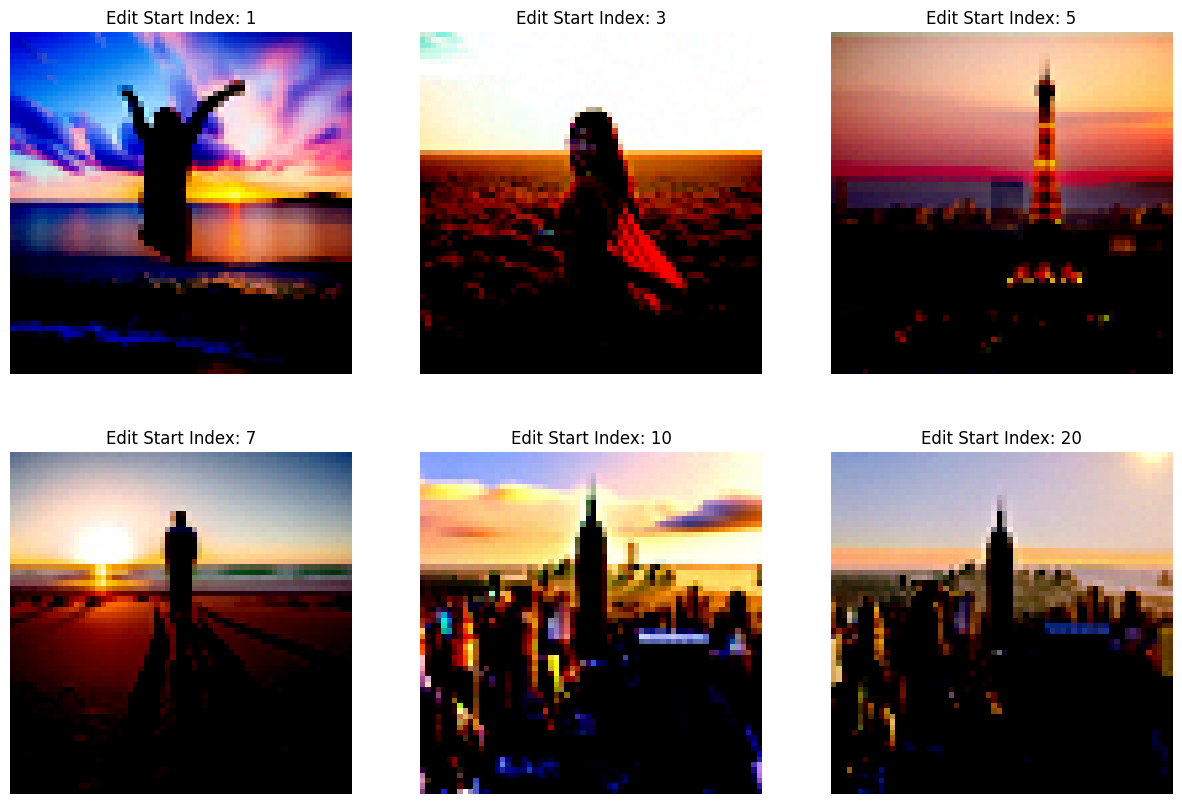
To evaluate the effect of inference steps on image quality, I tested with 5, 20, and 50 steps. Unsurprisingly, 50 inference steps produced the best results, showcasing fine details and higher fidelity to the prompts. Among the outputs, the "rocket ship" prompt was the most creative, generating imaginative and visually striking results. While the model generally aligns well with the prompts, occasional discrepancies highlight its limitations, particularly for simpler or abstract concepts.
































 p>
Fifth epoch.
p>
Fifth epoch.

